DNAシーケンスをアミノ酸シーケンスに変換してアライメントしたwork-conc.ptnファイルから進化系統樹を推定する作業を行う.系統樹推定のプログラムとしてはMolphyを用いる.~shimo/class/enshu200209ディレクトリにある実例をこのページでもクリックして見れるようにしてあるので,それを参考にすること.
1.まずwork-conc.ptnを覗いてみよう.このままでは見づらいので,
protst -a work-conc.ptn > work-conc-ptn.txt [enter]
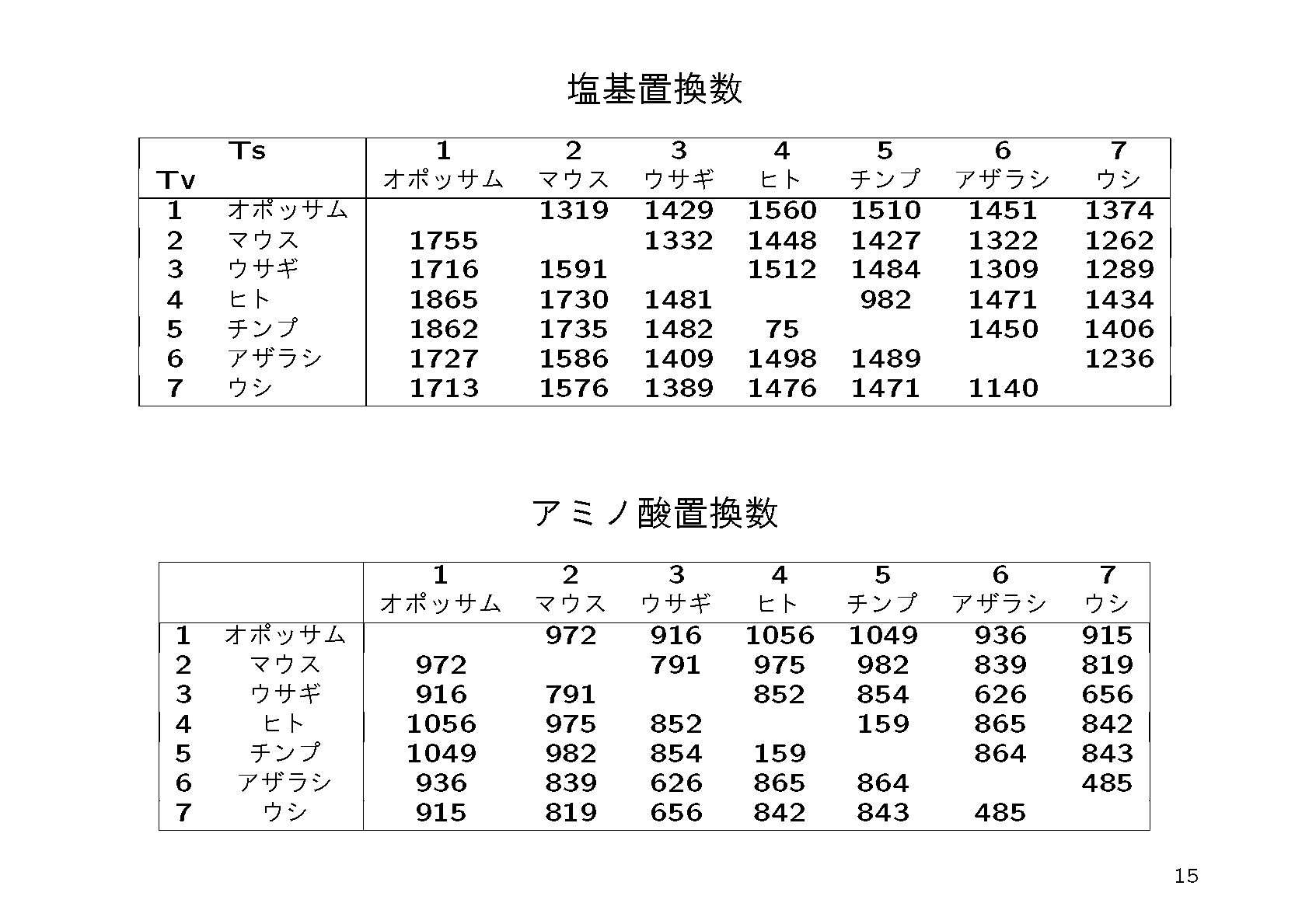
と形式を変換してから見ると良い.work-conc-ptn.txtにある"CONSENSUS"というのは入力した配列の各列で最も頻度の多かったアミノ酸を並べたシーケンスである(多数決で決めたということ).このCONSENSUSと同じアミノ酸はドットで表示され,それと異なる場合だけアミノ酸のアルファベットが書かれている.このように共通祖先から進化するにしたがってDNAが少しずつ変化する.比較的最近枝分かれしたばかりの生物(例えばヒトとチンパンジー)ではDNAの違いはごくわずかであるが,ずっと昔に枝分かれした生物(例えばヒトとイヌ)ではDNAの違いも大きい.逆にこの違いの情報を利用して,生物がどのような順序でいつころ分岐したかを推定することが可能である.
2.最初に近隣結合法(neighbor-joining, NJ法)を用いて推定を行う.コマンドは
cmd311 [enter]
である.このシェルスクリプトの内容は
#!/usr/local/bin/bash
# molphy nj analysis
outgroup=24
file=work-conc
protml -mfD $file.ptn > $file.dis
njdist -o ${outgroup} -w -t$file-nj -T$file-nj $file.dis > $file.nj
mv njdist.eps $file-nj.eps
repnamegb $file-nj.eps > $file-nj-name.eps
bbfix $file-nj-name.eps
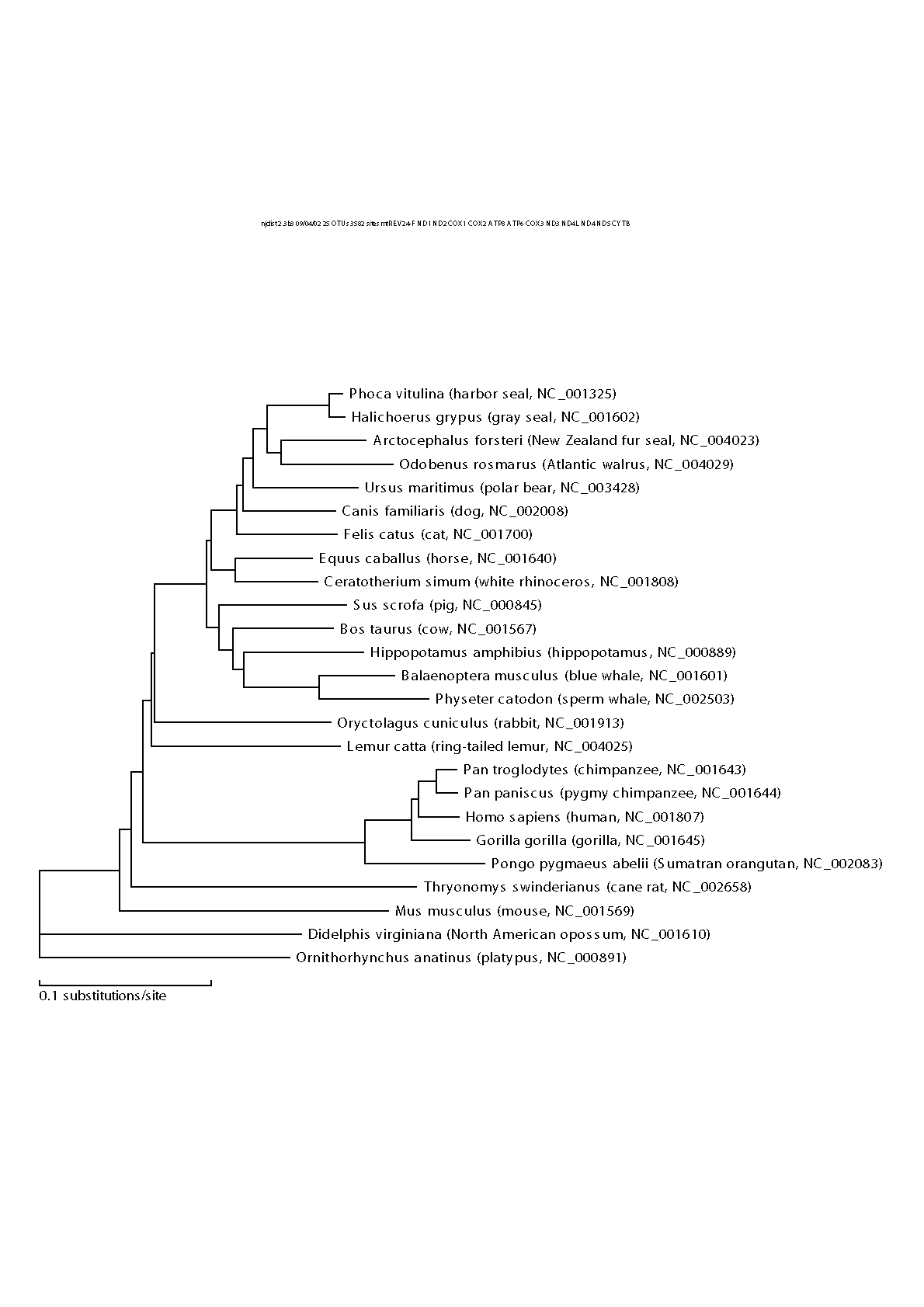
である.ここでoutgroup=24というのは後で述べる方法によって自分で変更する必要がある.NJ法ではまずDNAシーケンス間の「距離」,すなわち平均置換数をもとめる.アミノ酸のランダムな変化は時間にほぼ比例(分子時計という)起こると考えられており,距離は比較している生物が分化してからの時間に比例しているとみなしてよい.最も簡単に距離を求めるには,まず配列間でアミノ酸が異なる個数を数え,それを配列長で割ればよい.ここでは,マルコフ過程という確率モデルを用いて,もう少し高度な計算を行っており,同じ場所で複数回の置換が起こった可能性も考慮している.これを行っているのが "protml -mfD work-conc.ptn > work-conc.dis"である.ここでwork-conc.disはシーケンス間の距離行列である.距離行列からNJ法で系統樹を推定しているのが"njdost -o 24 -w -twork-conc-nj -Twork-conc-nj work-conc.dis > work-conc.nj"である.NJ法は,距離行列とつじつまが合うような系統樹を探し出すアルゴリズムである.結果のグラフィックスはEPSファイルとしてnjdist.epsに書かれるが,namegb.txtにかかれた情報をもとに生物の名前を書き込んだものがwork-conc-nj-name.epsである.
さて,自分でNJ法を行う場合はまずoutgroup=1などと適当な値を設定してcmd311を実行してみる.出力されたwork-conc.njをみると系統樹がテキスト形式で入っている.このなかで他の生物と最も遠い親戚にあたる生物が直接ついている枝の番号を読み取る.ここではNC_000891 (学名Ornithorhynchus anatinus,通称名platypus,カモノハシ)は,他の哺乳類とは最も遠い親戚なのでこれがついている枝の番号24を読み取る.そしてこの番号をcmd311のoutgroup=24に書き込んで再びcmd311を実行する.
outgroupは系統樹の根を指定している.DNAシーケンスを比較して得られる系統樹は本来根の位置が分からない木(unrooted tree)である.そこであらかじめ最も遠縁と分かっている生物(すなわちアウトグループ)を含めて系統樹を推定し,このアウトグループのついている枝が根の位置であると考える.
NJ法による推定結果はwork-conc-nj.treにもテキスト形式で書かれている.このカッコ形式の意味は先ほどのグラフィックスによる結果と見比べれば理解できるだろう.実数は枝の長さである.この枝の長さの情報を取り除いて系統樹の形だけをカッコ式で表したのがwork-conc-nj.tplである.
与えられた生物種に関して,可能なすべての系統樹の組み合わせ数は,非常に大きい.(階乗のオーダ).系統樹の探索空間については, Joe Felsensteinによるこの資料を参考にせよ.
3.NJ法で求めた系統樹は必ずしも信頼性が高いとはいえない.これに対して最尤法(Maximum-likelihood method, ML法)はよりよい方法と言われている.ML法では候補となる系統樹毎にそのもっともらしさの指標である尤度を進化確率モデルに基づいて計算する.そして最も尤度が高い系統樹を最尤系統樹として推定結果とする.実際には尤度の対数をとった対数尤度を計算して比較する.
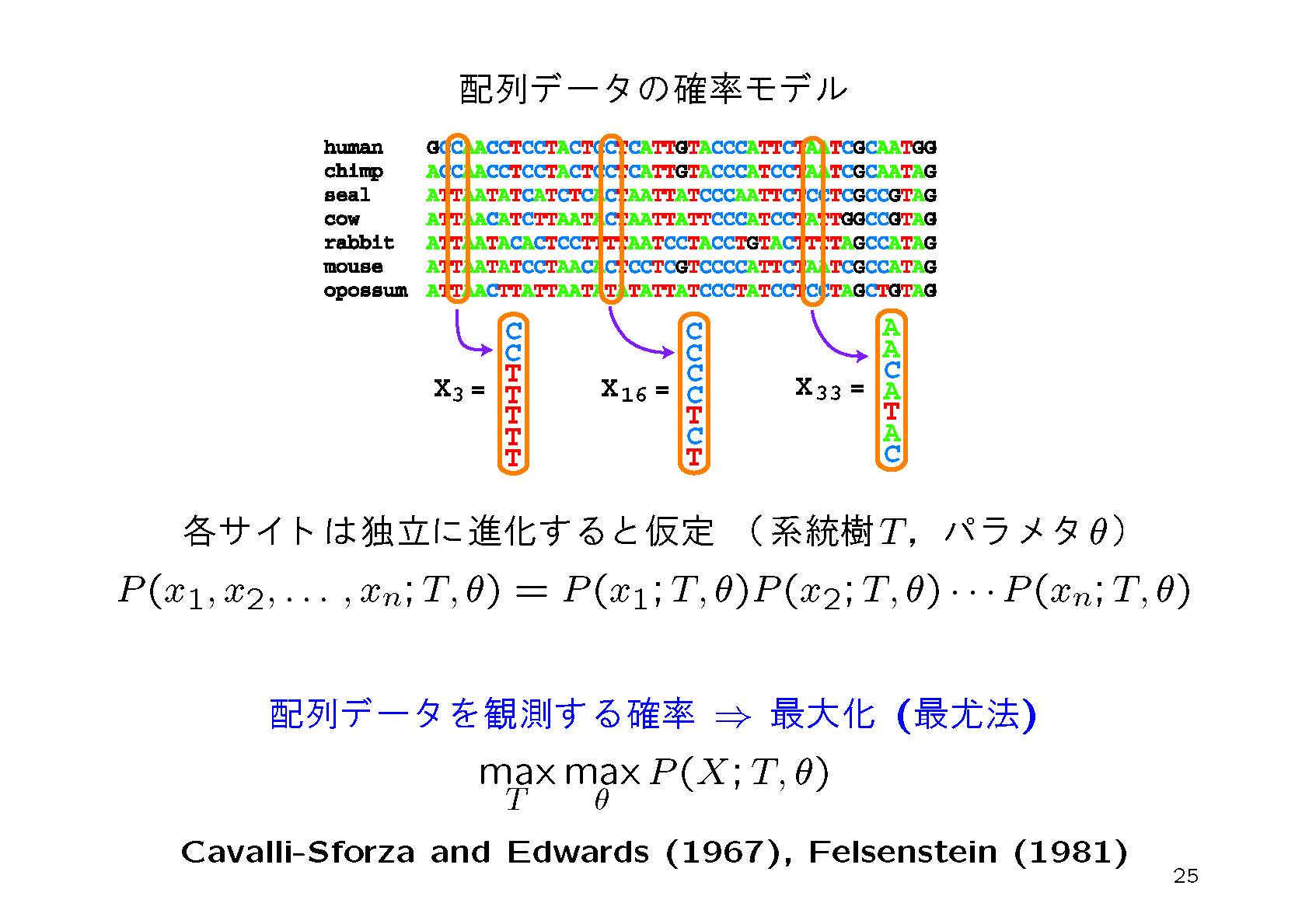
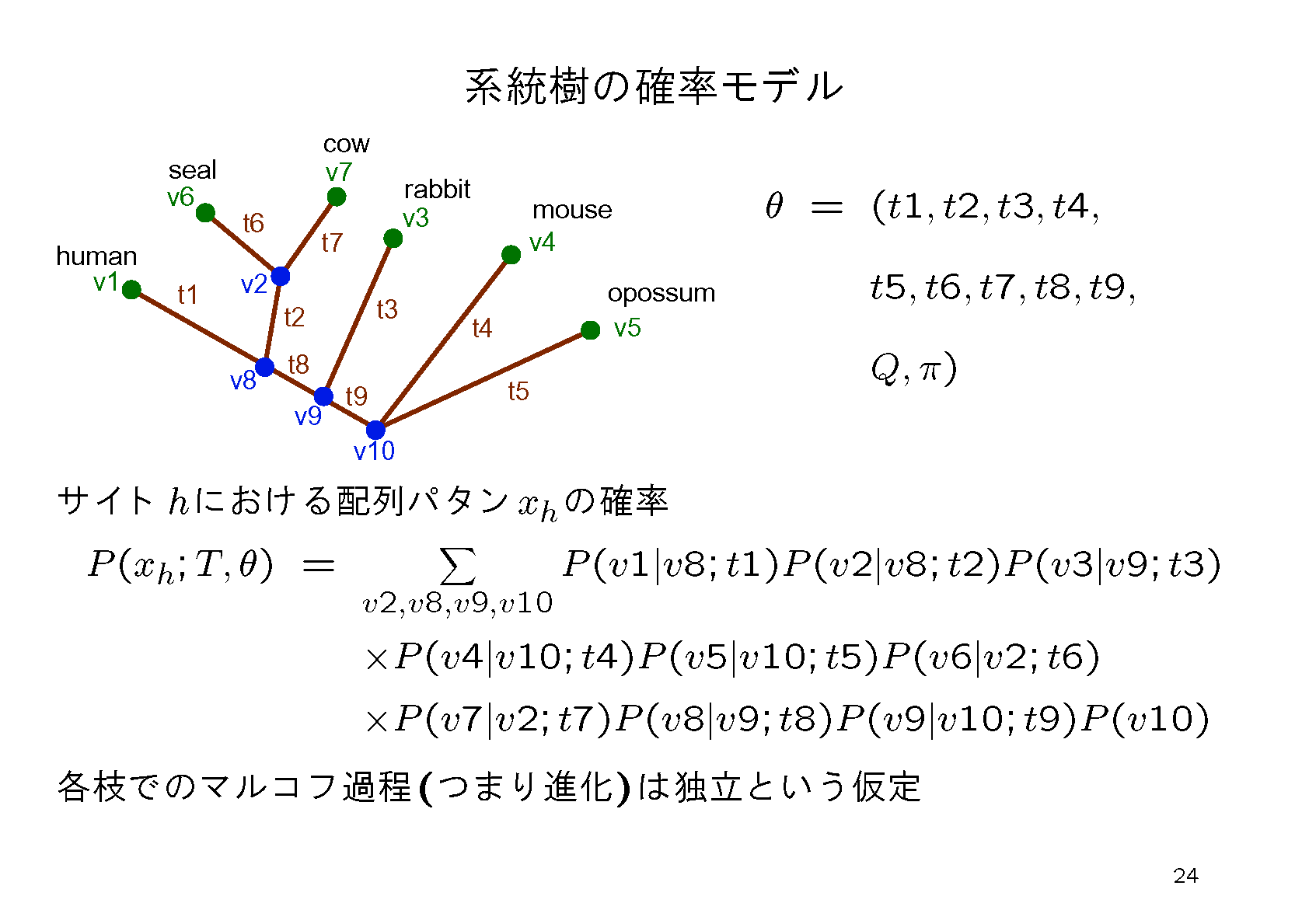
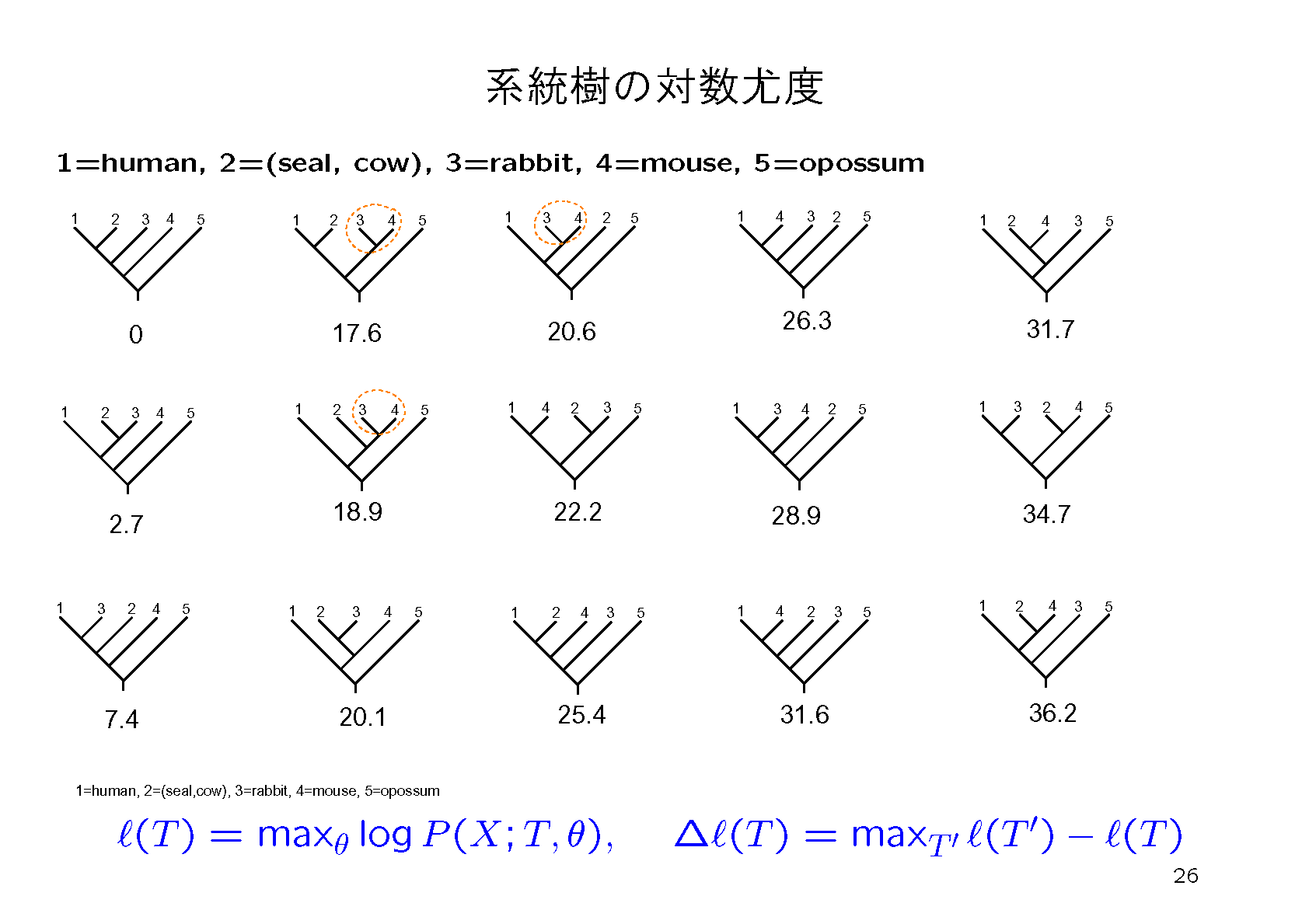
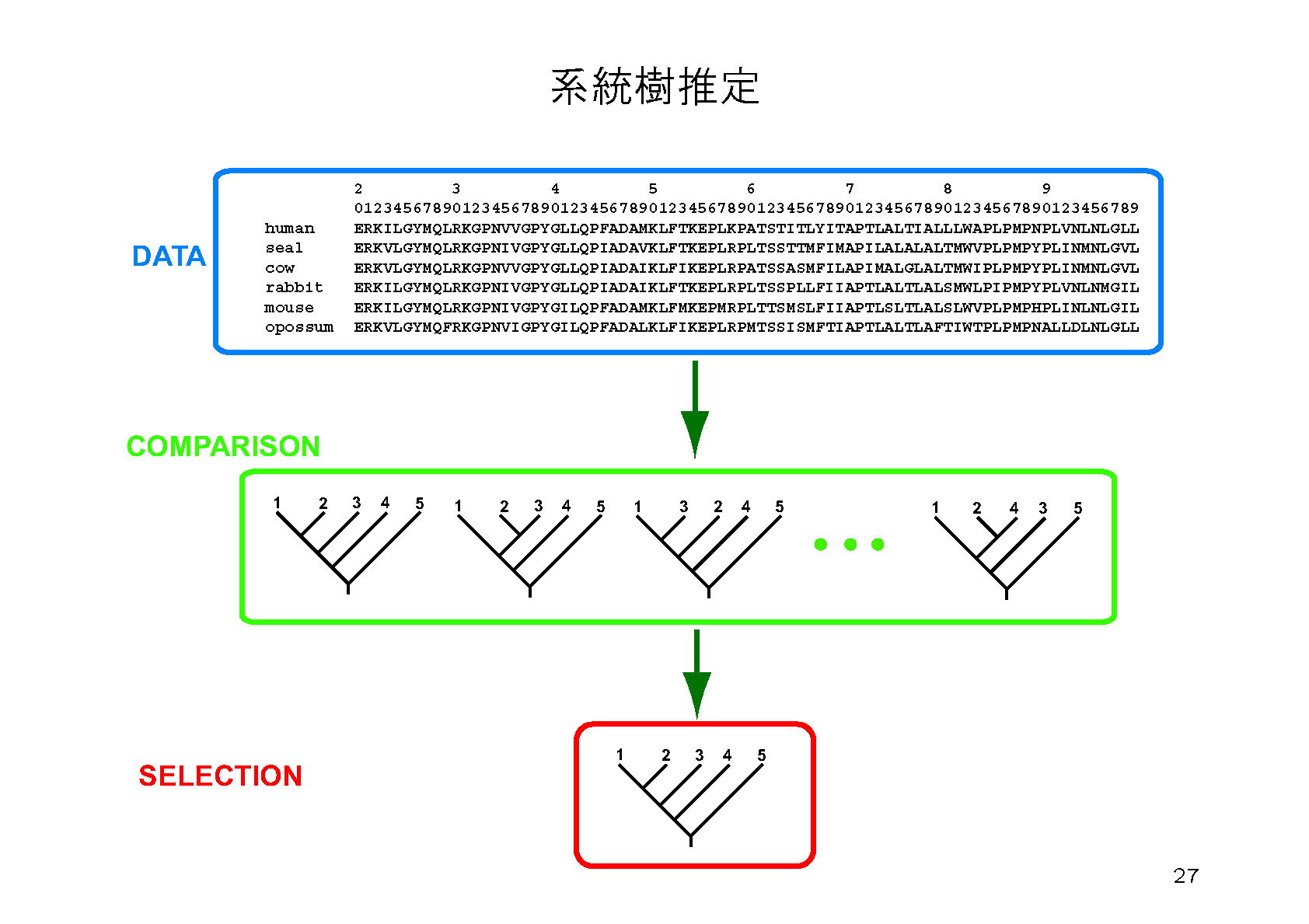
ML法の問題点は尤度の計算に時間がかかることである.そこでNJ法で求めたwork-conc-nj.tplから出発して,尤度を大きくすうるように系統樹を少しずつ変更して行き,もうそれ以上尤度を大きく出来なくなったら最尤推定の近似とみなすという方法が考えられる.これを実行するコマンドは
cmd331 [enter]
である.結果はwork-conc.mlr, work-conc-ml.tpl, work-conc-ml.tre, work-conc-ml.eps, work-conc-ml-name.epsなどに書かれているので内容を確認する.このようにして得られた系統樹より,もっと尤度の高い系統樹があるかもしれないが,すべての系統樹をくまなく探索することは,系統樹の数が多すぎて不可能である.したがって,系統樹探索では,何らかの近似手法が必要になる.
得られた系統樹work-conc-ml-name.epsを見ると,枝に数値がついている.これはローカルブートストラップ確率(LBP)と呼ばれて,その枝の信頼性を測る目安である.これが小さい枝はあまり信頼できない.この信頼性は,先ほど述べたような近似手法とは無関係であることに注意する.むしろ,信頼性の計算では,尤度を最大にする系統樹が探索できたと仮定している.しかし尤度を最大にしていても,「データのバラツキ」の影響で,真の系統樹が見つけられたとは限らないのである.つまり,一般に「尤度最大の系統樹」と「真の系統樹」は等しくない.そこで,データのバラツキを考慮して,推定結果の信頼性を確率で表現している.ここでは根のほうからLBP=74, 86の枝はあまり信用できない.次の97は一見すると十分高いのだが,それもあわせてこれら3個の枝の信頼性を次に調べる.
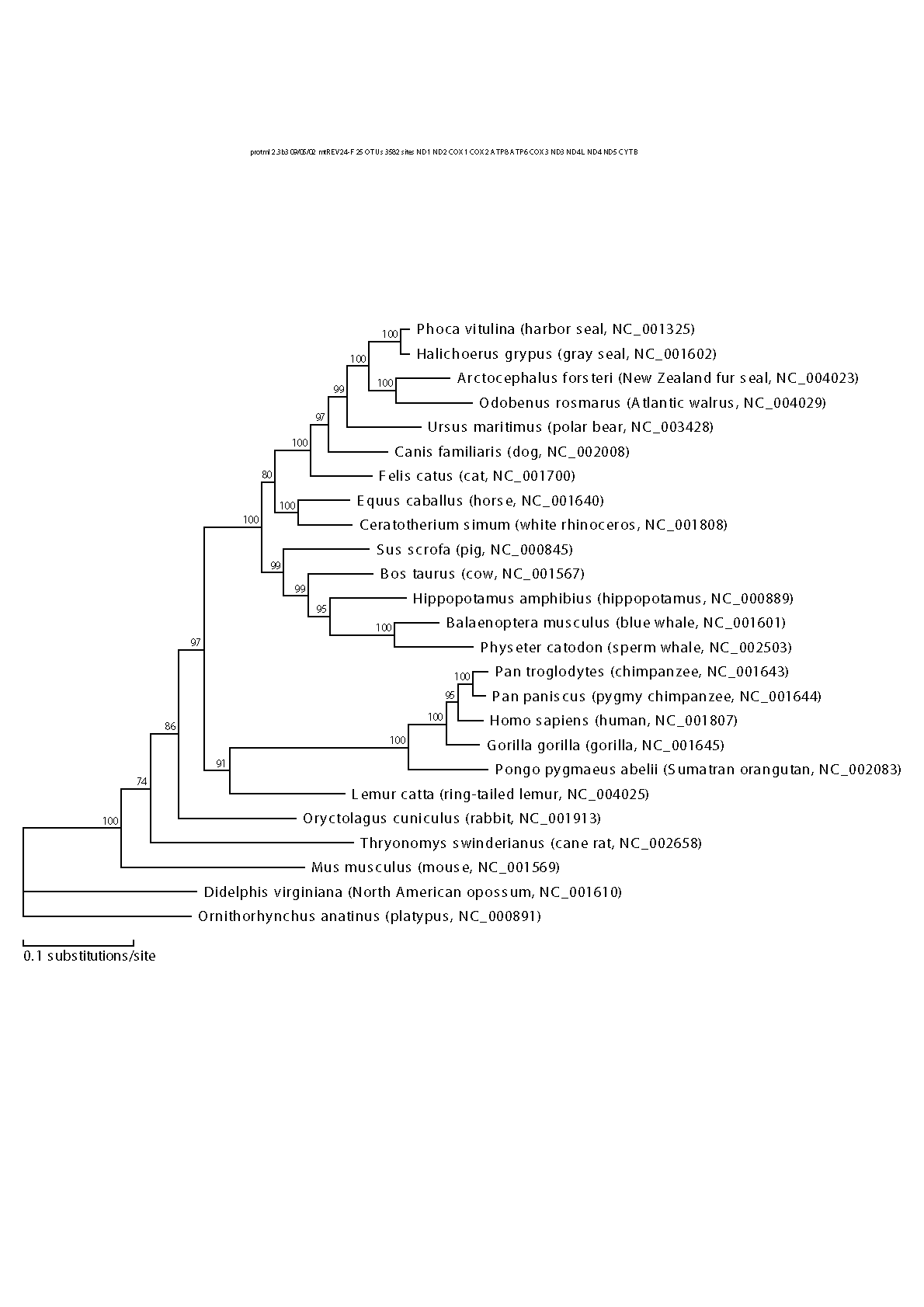
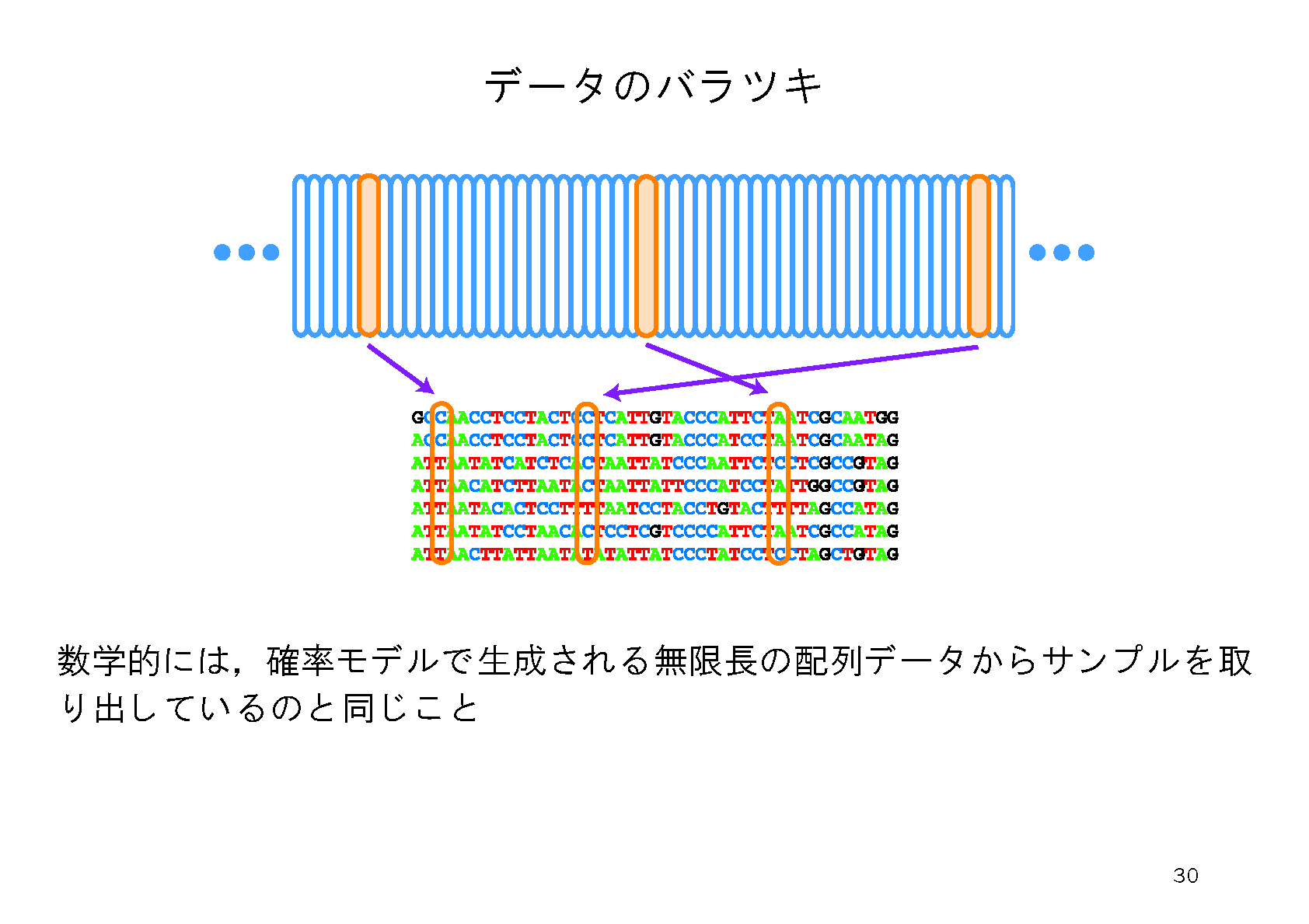
ブートストラップ法というのは,データに内在するバラツキを調べるためのアルゴリズムである.観測したアミノ酸配列からランダムに重複を許して配列を抜き出すと複製データができる.擬似乱数をもちいて複製データを多数(例えば10000個)作成し,どの系統樹が選ばれるか,どの枝が含まれているかなどの頻度からブートストラップ確率を計算する.
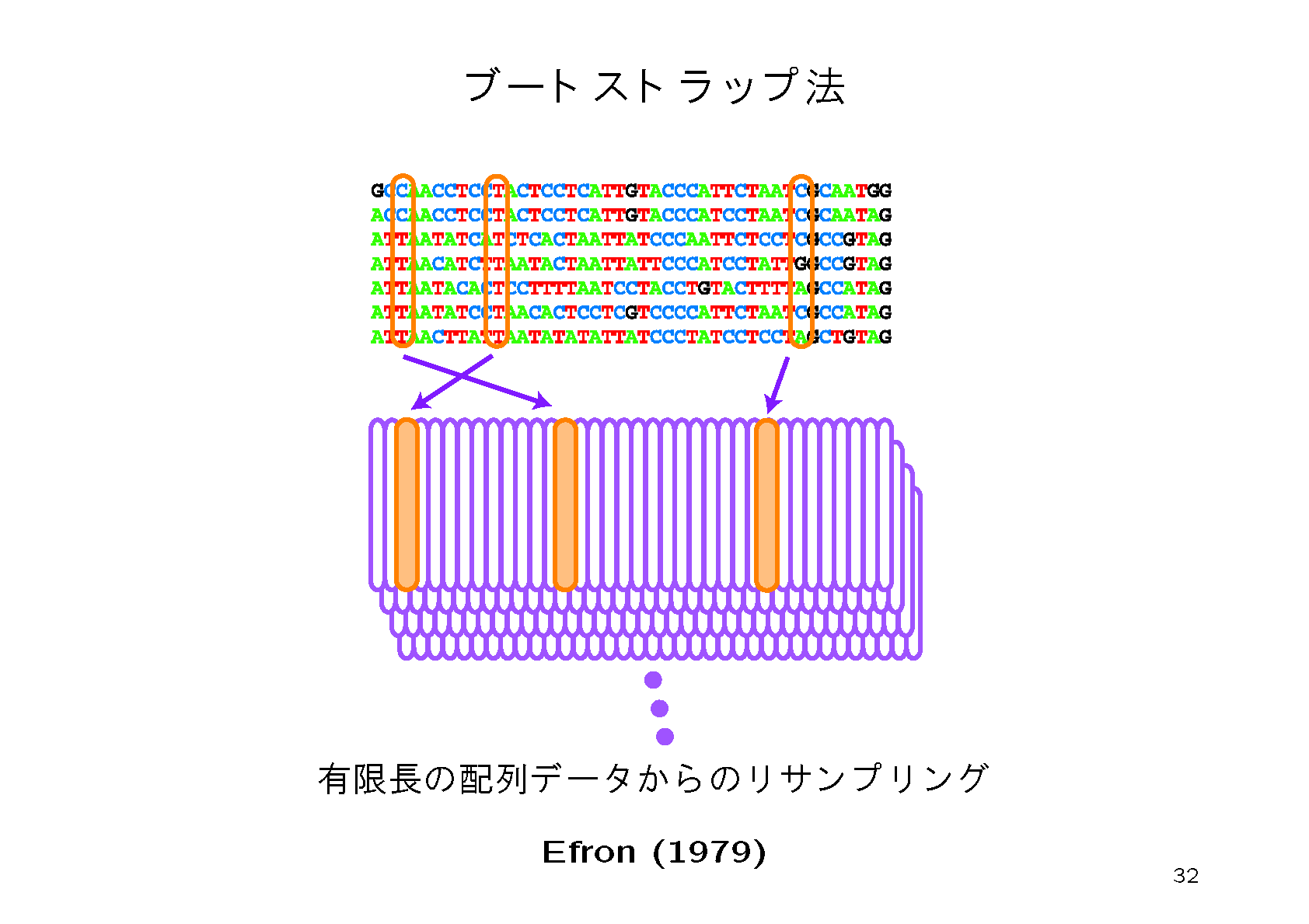
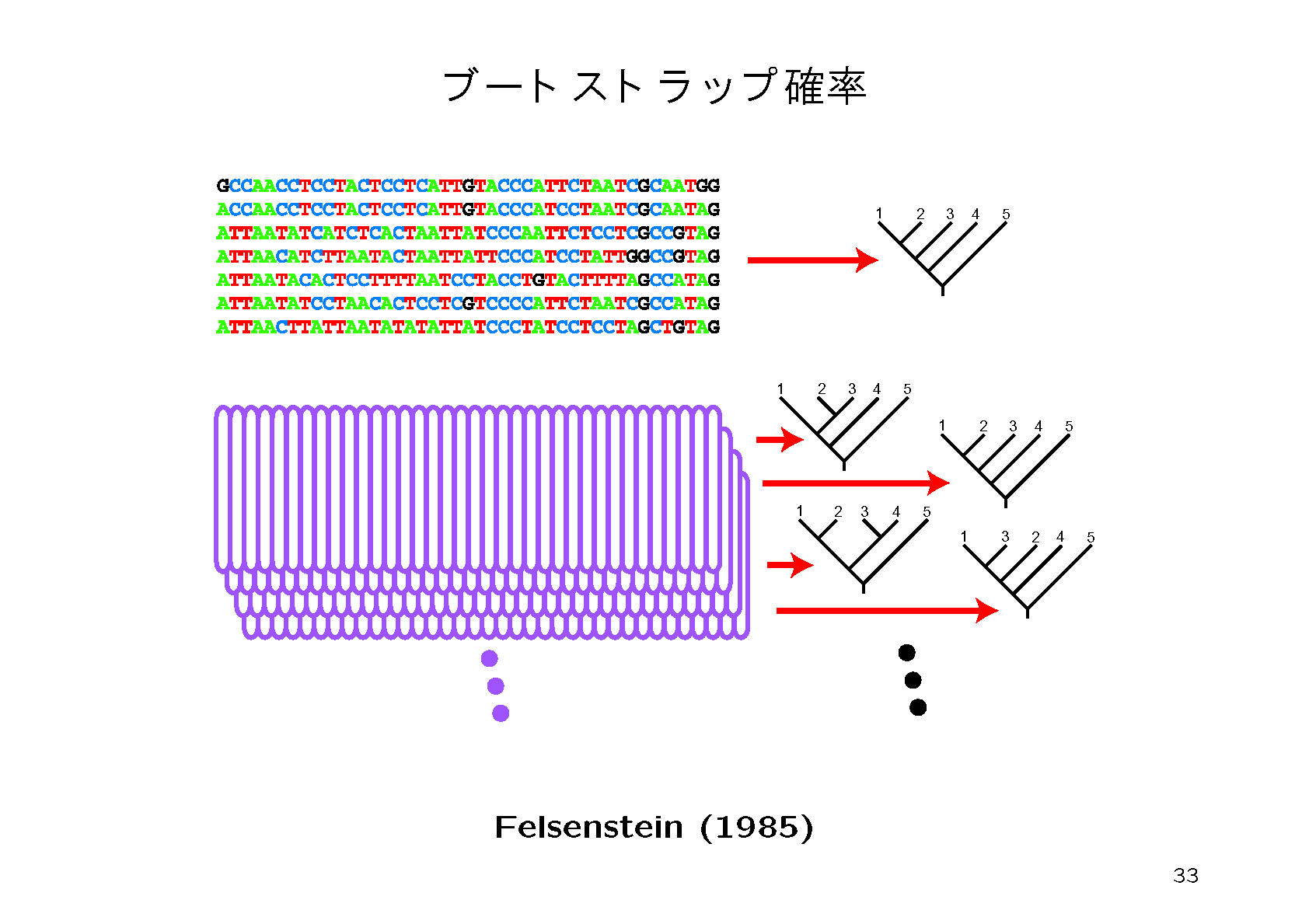
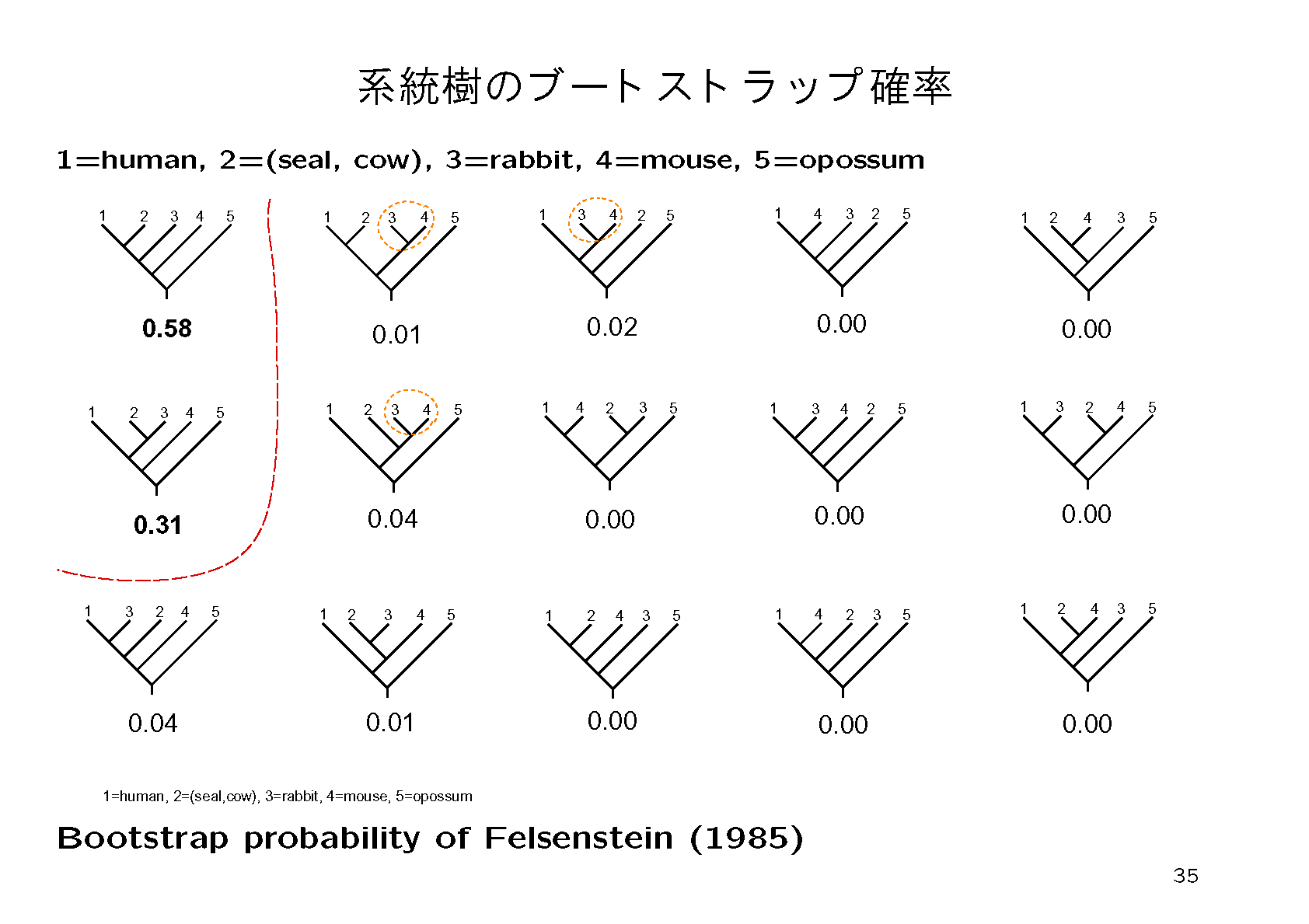
4.信頼性の低かった枝をより詳しく調べるために,次のように系統樹の候補者リストを作成し,それらすべてについて尤度を再計算する.work-conc-ml.tplを編集してwork-conc-constraint.tplを作成する.これは先ほどの3個の枝の長さをゼロに縮め,不確定な部分のカッコを { } に変更したものである.たとえばもとの系統樹が (((((A,B),C),D),E)F))という構造の場合にA,B,C,D,Eの順序が不確定の場合には({A,B,C,D,E},F)とする.こうするとA,B,C,D,Eから作られる部分系統樹のあらゆる組み合わせに展開される.たとえば,(((((A,B),C),D),E)F))や((((A,B),(C,D),E)F))などの組み合わせ105通りに展開される.この展開した系統樹一覧を書き出すためのコマンドが
cmd351 [enter]
である.結果はwork-conc-user.tplに入る.これは近似的に尤度を計算していてその大きい順に展開されている.この105通りの系統樹は,解析の次の段階では系統樹の候補者リストとして利用される.これら候補系統樹のすべてに対して,さらに正確な尤度を計算して尤度を最大にする系統樹を得るには
cmd371 [enter]
を実行する.この計算には比較的時間がかかるので,バックグラウンドジョブとして
cmd371 & [enter]
として実行したほうが良いかもしれない.(あやまって何度も同じコマンドを実行しないこと! バックグラウンドジョブのことが良く理解できていないならばやらないこと.) 実行結果はwork-conc-user.mlrとwork-conc-user.treに書かれている.尤度を最大にするのは105個の候補系統樹のうち7番目の系統樹でグラフィックはwork-conc-user-name.epsである.
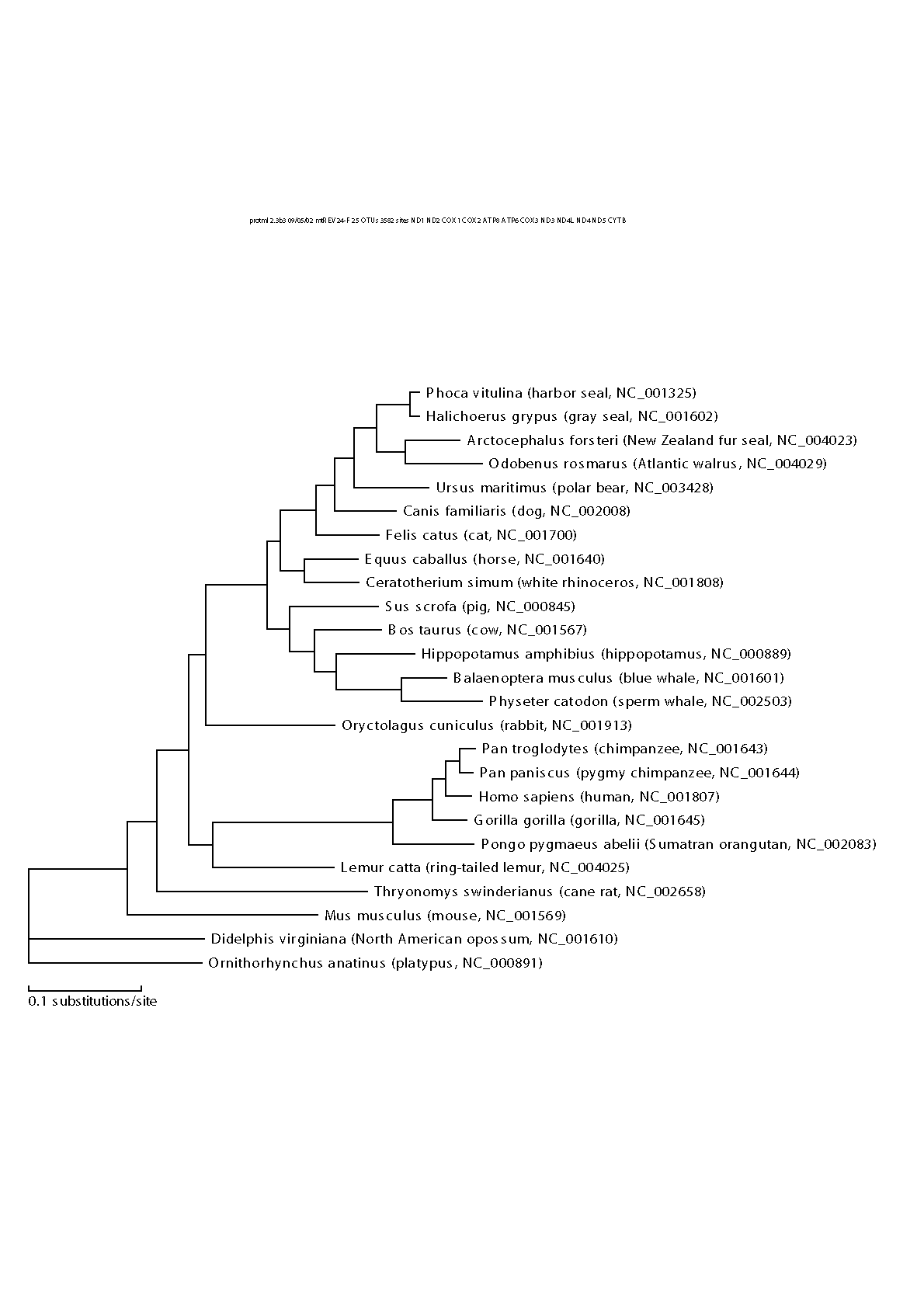
5.後で用いるために,以下のファイルを作成しておく.まずwork-conc-constraint.tplを作成するときに出てきたA,B,C,D,E,Fなどの部分系統樹をwork-conc-clade.txtというファイルに書いておく.そしてwork-conc-user.tplを編集して最初の行をwork-conc-user.tplのようにしておく.つまり一行目は系統樹の個数をあらわす整数だけ残し,あとは#をつけてコメントにする.