epiで並列Rを使う(2010/05/21)
2010年5月19日
18:12
ここではepi00にアカウント名shimoでログインして作業します.
次のようにして,アカウント名kanriのホームにあるtest20100517.tgzを自分のホームにコピーして,内容を展開してください.
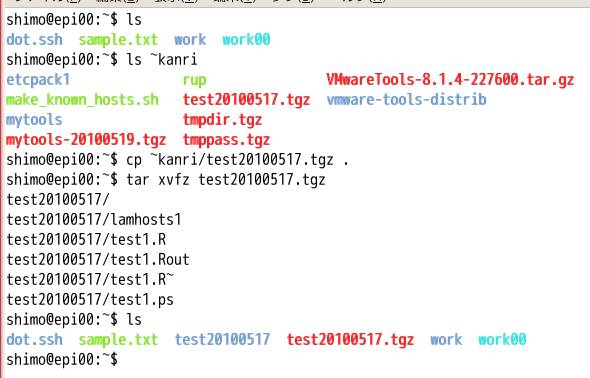
画面の領域の取り込み日時: 2010/05/19 18:17
展開してできたディレクトリtest20100517に移動します.test1.Rとlamhosts1を
コピーしてtest2.Rとlamhosts2をつくります.
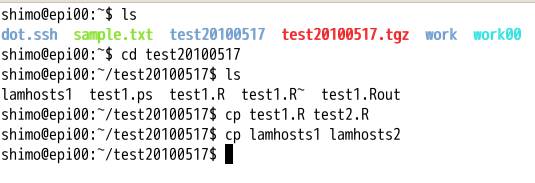
画面の領域の取り込み日時: 2010/05/19 18:19
これをemacsで編集します.emacs lamhosts2を実行してください.
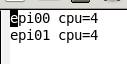
画面の領域の取り込み日時: 2010/05/19 18:22
これはepi00はcpu=4個,epi01はcpu=4個という設定です.今回はこのままつかいます.変更するときは,Control-X Control-Sで保存してください.次にContorl-X Control-Fで別のファイルを開きます.test2.Rを開いてください.
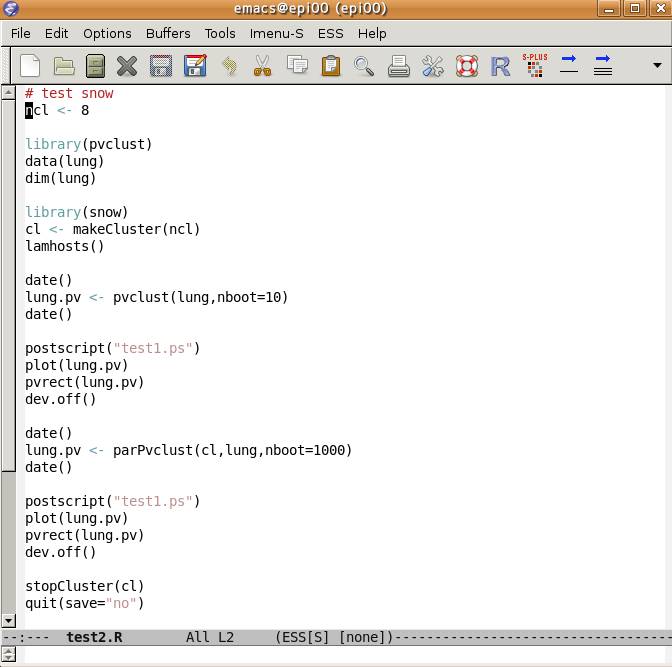
画面の領域の取り込み日時: 2010/05/19 18:24
最初の ncl <- 8が利用するcpu数の合計です.ここではこのままにしておきます.変更した場合,Control-X Control-Sで保存してください.Control-X Control-Cで終了です.
~kanri/bin/rupを実行すると,各ノードの稼働状況がわかります.(以下の説明中で~kanri/rupと記述してあるのは~kanri/bin/rupに読み替えてください).途中でControl-Cで止めてください.ここではepi00とepi01がパワーオンしていてload averageが低く,他の人が計算してないのがわかります.
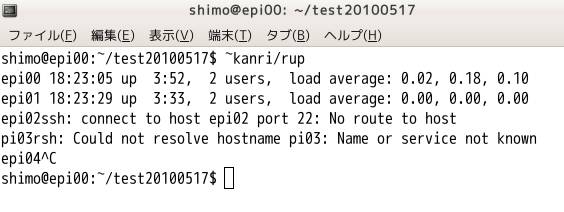
画面の領域の取り込み日時: 2010/05/19 18:28
lamboot lamhosts2を実行します.

画面の領域の取り込み日時: 2010/05/19 18:28
R CMD BATCH test2.R >& test2.log & とすると実行開始です.エラーなどはtest2.logに書き出されます.実行はバックグラウンドにしたいので,最後に&をつけています.こうすると,他の作業をしたりログアウトしたりしても,Rの計算は動き続けます.

画面の領域の取り込み日時: 2010/05/19 18:29
topとするとepi00での状況がわかります.load averageの時間平均(過去何分間かの平均値)がだんだん4にちかずきます.qで終了.
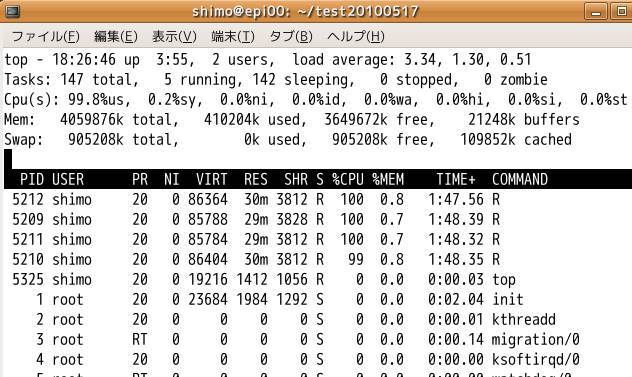
画面の領域の取り込み日時: 2010/05/19 18:31
rupをみると,やはりepi00でもepi01でも4くらいです.

画面の領域の取り込み日時: 2010/05/19 18:32
rupというのは,shell scriptで書いた次のコマンドです.あとで自分のホームにbinというディレクトリをつくり,その中にコピーしてください.いちいち~kanri/bin/rupと打たずにrupだけで使えるようになります.(次にログインするとき,自動的に$HOME/binにpathがとおるように.profileが設定されています.)
shimo@epi00:~$ cat ~kanri/bin/rup
#!/bin/sh
for i in
epi00 epi01 epi02 pi03 epi04 epi05 epi06 epi07 epi08 epi09 epi10 epi11 epi12
epi13 epi14 epi15 epi16 epi17 epi18 epi19 epi20
; do
echo -n
$i
rsh $i
uptime
done
rsh epi00 uptime, rsh epi01 uptime, ..., rsh epi20 uptimeを順番に実行するだけです.自分の使いやすいように,あとで各自編集して工夫してください(本拠地」のホスト名を最初にして並べ替えるなどする).epiではrshの部分はsshとしても同じ動作になるように設定してあります.
test2.Rの計算は数分で実行が終わります.できたファイルをみます.
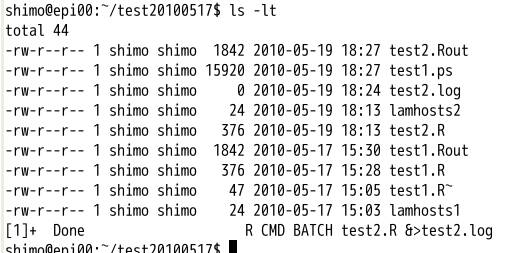
画面の領域の取り込み日時: 2010/05/19 18:34
test2.Routをみます.cat test2.Routとするかlv test2.Routかemacs test2.Routか,どれでも好きな方法で見てください.
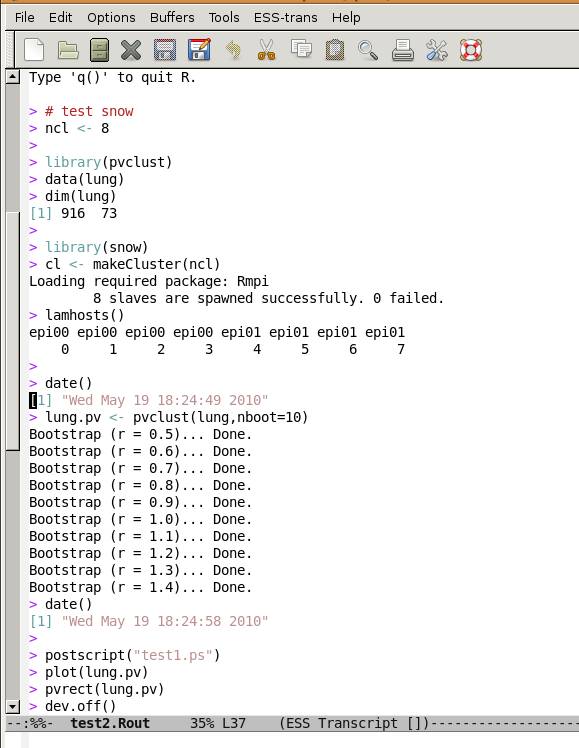
画面の領域の取り込み日時: 2010/05/19 18:37
うえをみると,epi00で4個,epi01で4個のcpuが確保できたのがわかります.はじめはcpuを1個だけつかってpvclust(反復数=10)を実行です.時間をみると,9秒くらいですね.
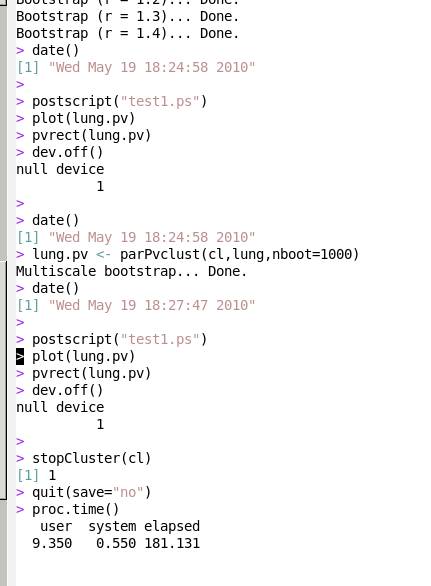
画面の領域の取り込み日時: 2010/05/19 18:38
次に8cpuをつかった並列実行です.反復数=1000に増やしたので計算量はさっきの100倍です.計算時間は169秒なので169/9=18.8倍です.したがって,計算速度が100/(169/9)=5.3倍早くなったことになります.cpuを1個から8個にふやしたので8倍になってくれればうれしいですが,実際には多少下がることが多いです.なおcpuが1個のときの計算が8秒となっていますが誤差が1秒あります.もし並列化の効率を正確に測るならcpu=1のときの反復数=10をせめて100くらいにする必要があります.
実はepi00とepi01という2台の仮想マシンは 1台のパソコンで動いている仮想マシンです(cpuも本当は1個でコア数が4つまりquad core :quadは4ですよね.でも2倍してコア8としてあつかえるらしい).見かけ上8cpuとしてあつかえるようなので,epi00は4cpu,epi01も4cpuの仮想マシンとしていますが,本当に8cpuあるわけではないです.なおここではvmware workstation 7という製品をつかっているので複数の仮想マシンが動かせます(忘れていましたが,本当はもう1個うごかしていて3個の仮想マシンが動いていました).無料のvmware playerだと同時に1個しかパワーオンできないみたいです.vmware server (無料)なら複数の仮想マシンがパワーオンできるようですが,まだ試していません.
画面の領域の取り込み日時: 2010/05/21 15:34
epi00でdmesgを実行してCPUに関係する情報をみると
[ 0.216371] CPU0: Intel(R) Core(TM) i7
CPU 960 @ 3.20GHz stepping 05
[ 0.490750] CPU1: Intel(R) Core(TM) i7
CPU 960 @ 3.20GHz stepping 05
[ 0.650269] CPU2: Intel(R) Core(TM) i7
CPU 960 @ 3.20GHz stepping 05
[ 0.809787] CPU3: Intel(R) Core(TM) i7
CPU 960 @ 3.20GHz stepping 05
[ 0.810051] Total of 4 processors activated
(25654.12 BogoMIPS).
となっています.25654.12 BogoMIPSというのが,だいたいの計算速度を表します.
ちなみに,数日前に実行したtest1.Routのほうをみると下図のように115秒で実行されています.時間は115/9=12.8倍になったので,計算速度が100/(115/9)=7.8倍です.ほぼ8倍になっていて理想的です.

画面の領域の取り込み日時: 2010/05/19 18:47
このtest1.Rを実行したときは,epi00も4cpu, epi01も4cpuで今回と同じ設定なのですが,epi00は1台目のパソコン,epi01は2台目のパソコンで実行しました(ただしvmwareの優先順位をさげてCPUを半分だけつかう設定にしてありました.パソコンでメールを読んだり別の仕事の邪魔にならないように,これが標準の設定です).それで仮想PCをつかう無駄がなくて,ほぼ理想的な結果でした.
計算がおわったら,最後にlamcleanを実行してください.

画面の領域の取り込み日時: 2010/05/19 18:54
これでepiでの並列Rの説明はおわりです.
-----------------------------------------------
#### 番外編(その1)
本当はあとの番外編(その2)を最初にやったのだけど,その待ち時間にこの(その1)をやりました...
**さっきの実験では1台のパソコン上でepi00,epi01, totoroという3台の仮想マシンが動作していた.totoroはアイドル状態だったけど,もしかしたら影響があるかもしれない.そこでtotoroをshutdownしてやりなおしてみる.
自宅からの作業ですが,実機がみえないせいで仮想マシンかどうかなんて全く分かりません.仮想マシンで動いてるtotoroのパワーオフもリモートから普通にできます.
さっきと同じように作業を進めます.epi00とepi01の2台の仮想マシンは1台のWindowsパソコン上で動いています.
画面の領域の取り込み日時: 2010/05/19 23:13
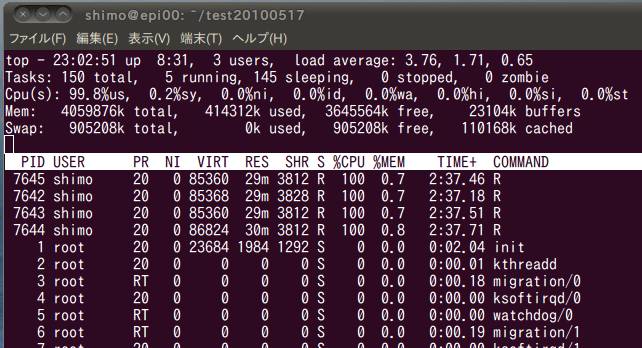
画面の領域の取り込み日時: 2010/05/19 23:13
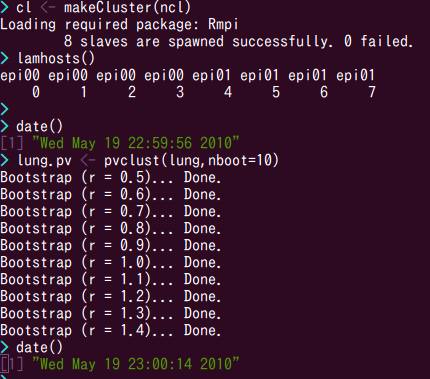
画面の領域の取り込み日時: 2010/05/19 23:16
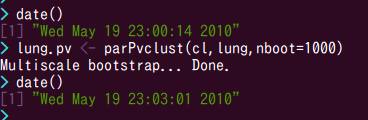
画面の領域の取り込み日時: 2010/05/19 23:17
結果は...cpu1個で8秒(さっきは9秒だけど,1秒差は測定誤差内).cpu8個で167秒(さっきは169秒でたった2秒差).したがって,アイドル中だったもう一台の仮想マシンtotoroの影響は実質的にほとんどなかったことになります.
---------------------------------------------------------
#### 番外編(その2)
同じ計算を別のPCクラスターでやってみます.研究室で最初2003年6月頃に稼働させたものです(/etc/hostnameのタイムスタンプをみると,kumaは2003/06/02, fan08は2003/06/09).当時の松岡研に在籍した山本君が下平研でも研究をすることになり,設定を全面的にやってくれました(感謝!).20ノード(cpuが2個ずつ)あり,合計40cpuとして扱います. dmesgを実行して確認すると,
ホストノードのkumaとkabaは
CPU0:
Intel(R) Xeon(TM) CPU 2.40GHz stepping 07
CPU1:
Intel(R) Xeon(TM) CPU 2.40GHz stepping 07
Total of
2 processors activated (9555.14 BogoMIPS).
計算ノードfan00,…,fan17は
CPU0: AMD
Athlon(tm) MP 2000+ stepping 02
CPU1: AMD
Athlon(tm) Processor stepping 02
Total of
2 processors activated (6651.90 BogoMIPS).
となっています.epi00のときは
[ 0.810051] Total of 4 processors activated
(25654.12 BogoMIPS).
だったので,fanに対するepiのコアあたりの速度比は(25654/4)/(6652/2)=1.9倍です.つまりlambootの指定で同じCPU数にした場合,epiクラスタのほうがkumaクラスタより2倍近く早いと予想できます.
並列Rを動かしてみます.まず計算ノードの空き状況をrupで調べます.
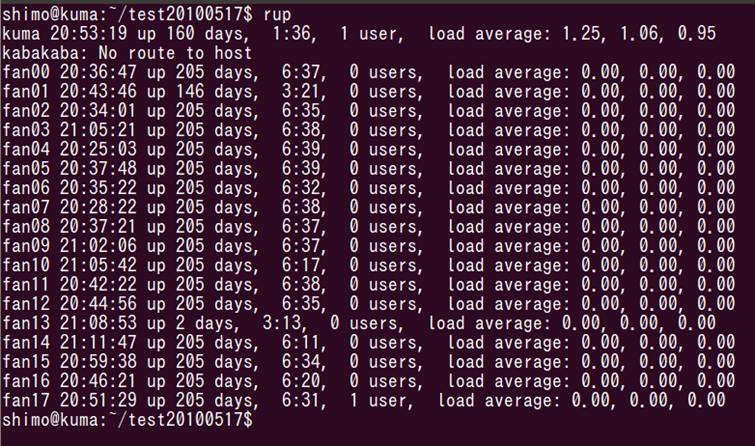
画面の領域の取り込み日時: 2010/05/19 20:53
空いてるみたいです(kabaは落ちてます).fan08, fan09, fan10, fan11を各cpu=2として,合計8cpuでやってみます.
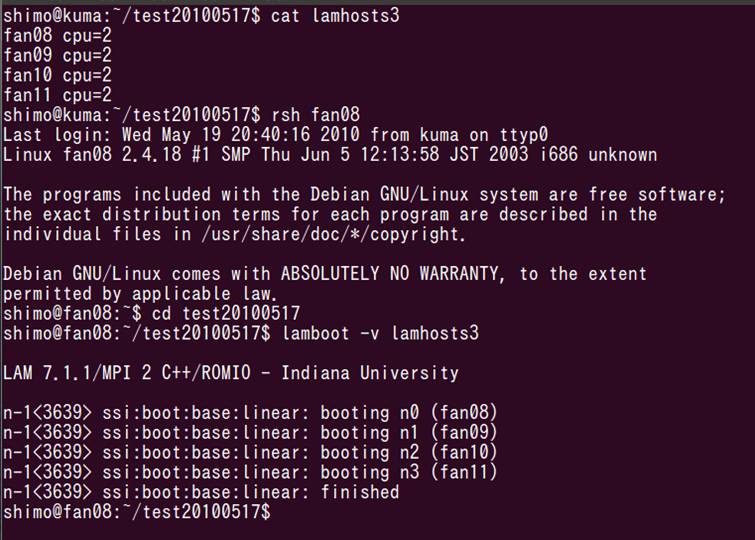
画面の領域の取り込み日時: 2010/05/19 20:58
無事lambootができたので,Rプログラムを実行します.内容はtest2.Rと同一です.
R CMD BATCH test3.R >& test3.log &

画面の領域の取り込み日時: 2010/05/19 20:59
topコマンドでfan08の様子を見ます.
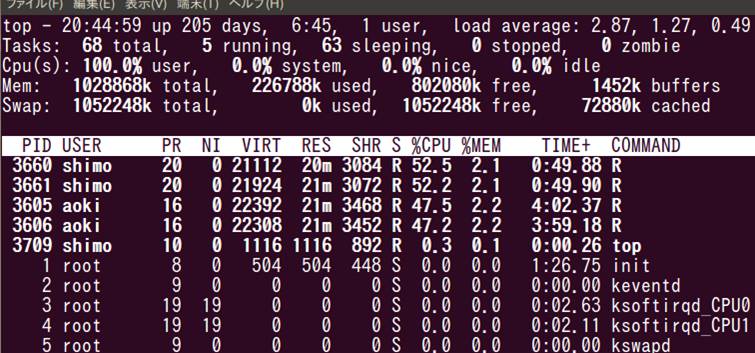
画面の領域の取り込み日時: 2010/05/19 21:01
あれ,shimoのRプロセスのほかに,aokiのRプロセスが動いてる!
load averageも2を超えてる.rupで全体をみてみると,fan08, fan09, fan10, fan11のload averageが2をこえてる
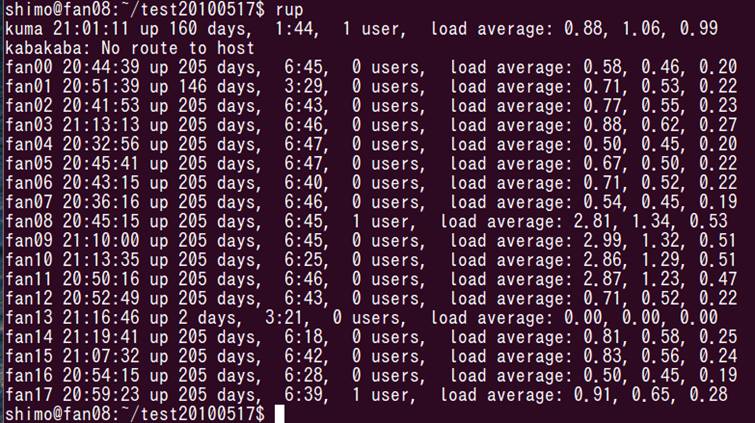
画面の領域の取り込み日時: 2010/05/19 21:01
ああ,aoki君も計算始めてしまったみたい.これでは計算速度が測定できません.というか,aoki君のほうが起動が一瞬はやかったじゃないか.私の方がaoki君の邪魔をしてるということです.一応,最後までやってみます.
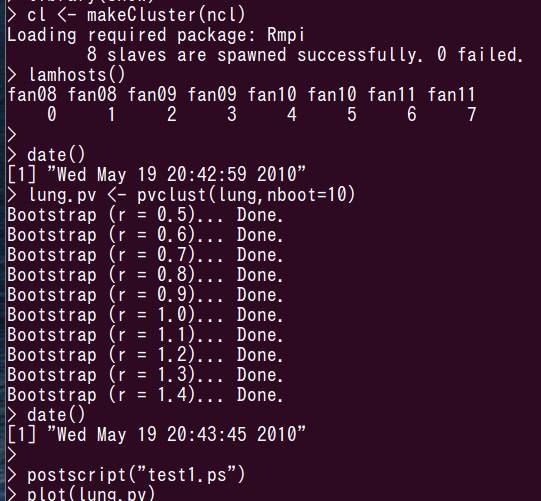
画面の領域の取り込み日時: 2010/05/19 21:11
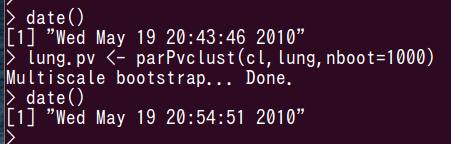
画面の領域の取り込み日時: 2010/05/19 21:12
CPUが1個だと46秒, CPU8個だと665秒ですが,二人が計算を実行しているので,本来より遅くなったはずです.どのくらい影響があったか,はっきりしないので,もう一度やり直します.
朝起きてみると,aoki君の計算は終わっていました.並列Rを実行してみます.
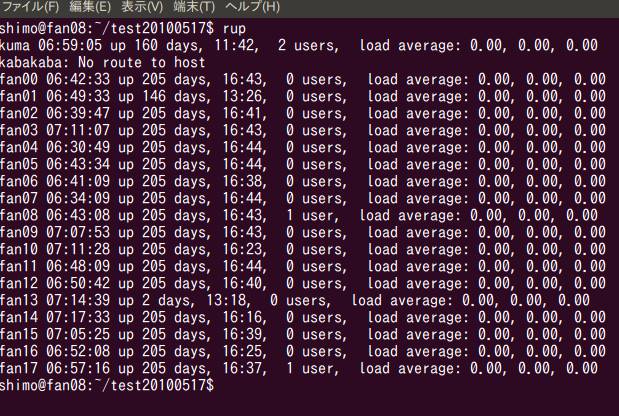
画面の領域の取り込み日時: 2010/05/20 6:59
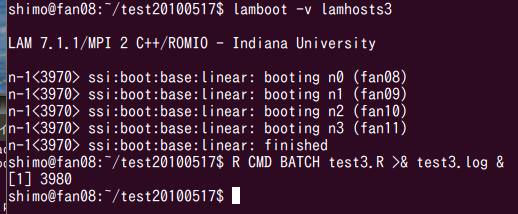
画面の領域の取り込み日時: 2010/05/20 7:00
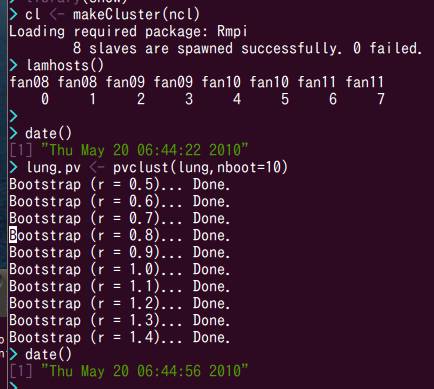
画面の領域の取り込み日時: 2010/05/20 7:18
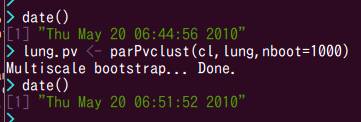
画面の領域の取り込み日時: 2010/05/20 7:19
CPU1個で34秒,CPU8個で416秒でした.CPUを1個から8個に増やして計算速度が100/(416/34)=8.2倍になったことがわかります.多少の誤差の範囲で,ほぼ理想的に効率が上がっています.
kumaクラスタとepiクラスタの計算速度を比較します.cpu8個の計算時間はfan08,…,fan11を使ったkumaクラスターは416秒.これにたいしてepi00+epi01(実はパソコン1台)でやったときは169秒だったので,同じCPU数をつかえば416/169=2.5倍くらいkumaよりepiのほうが速いことになります.
これは同じCPU数で比較した場合なので,もし40cpu全部使えばkumaは416*8/40=83.2秒くらいで計算が終わるはずなので,169/83.2=2倍くらい,epi00+epi01(実はパソコン1台)よりkuma全体のほうが速いことになります.つまり40cpuの古いクラスターは現在のパソコンの2台程度の能力です.当時の40cpuのクラスターと現在のパソコン2台の価格比は20倍くらいです.したがって,kumaからepiに乗り換えることによってコストパフォーマンスは20倍程度向上します.
それに燃費(電力消費)とか,おき場所と冷房の問題とか,管理コストとか,いろんな問題を解決します.
kumaクラスターは,今年中に総入れ替え(再インストール)したいと思います.システム設定の練習用とか,まだそういう意味はあると思う.学部生,修士の学生はkumaクラスターを利用はしても,システム管理をやる人は皆無になってしまいました.vmwareの仮想PC上でクラスタを構成すれば,もっと身近になって,管理とかにも少し手を出す学生が出てくるかもしれない.そういう教育上の意義もあると思います.
追記:タイムスタンプがおかしいので気づいたがfanはntpとか時計合わせの設定してなかったみたい.kumaとfan08で比べると

画面の領域の取り込み日時: 2010/05/20 8:54
となってます.